你有没有发现,现在很多 AI 回答最大的问题不是“答不上来”,而是“答得太像真的”。
它语气很稳定,结构很完整,甚至还会列出步骤、注意事项和看起来很专业的判断。
可真正危险的地方在于:你不知道它到底是根据什么说出这句话的。
很多人第一次听到 RAG,会把它理解成“给 AI 接一个知识库”。
这个理解不算错,但太浅。
知识库只是资料放在哪里。RAG 真正要解决的是另一个问题:
当 AI 给你一个答案时,你能不能判断这个答案到底靠不靠谱?
比如你在电商平台问客服:
我这个商品还能退吗?
一个普通大模型可能会根据常见售后规则回答:
一般情况下,签收 7 天内可以申请退货。
这句话听起来很正常,甚至很像客服话术。
但问题是:它真的知道你的订单状态吗?知道你买的是不是定制商品吗?知道商品有没有拆封吗?知道是否超过签收时间吗?知道当前店铺的退货政策是不是最新版吗?
如果这些信息都没有,它直接回答“可以退”,其实就是在没有证据的情况下装作知道。
RAG 真正要解决的,不只是让 AI 多读几份文档,而是让它在回答前先去找证据:订单状态是什么,商品类型是什么,售后政策怎么写,是否存在例外条款。只有这些证据足够支持结论,它才能回答;如果证据不够,它就应该说“不确定,还需要查询订单状态”。
所以我现在更愿意这样理解 RAG:
RAG 不是让模型知道更多,而是让模型的回答有证据、有边界、可追溯、可评测。
什么是 RAG:让模型先找证据,再回答问题
RAG = Retrieval-Augmented Generation,检索增强生成。
这个概念来自 2020 年 Lewis 等人的论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。这篇论文提出的核心思路,是把预训练模型的参数化记忆和外部检索得到的非参数化记忆结合起来,让模型在知识密集型任务中利用外部资料生成回答。但在今天的 AI 应用工程里,如果我们要把 RAG 用到客服、企业知识库、求职材料、内部系统,就不能只停留在“检索 + 生成”,还要继续解决引用、权限、拒答、评测和可追溯问题。
用更简单的话说:
RAG 不是让大模型只靠“脑子里记住的参数”回答,而是在回答前先去外部知识源检索相关资料,再把检索到的内容作为上下文交给模型生成答案。
基本流程可以理解成:
用户问题
↓
检索相关文档 / 数据 / 片段
↓
把检索结果作为上下文
↓
交给大模型生成回答
↓
返回答案 + 来源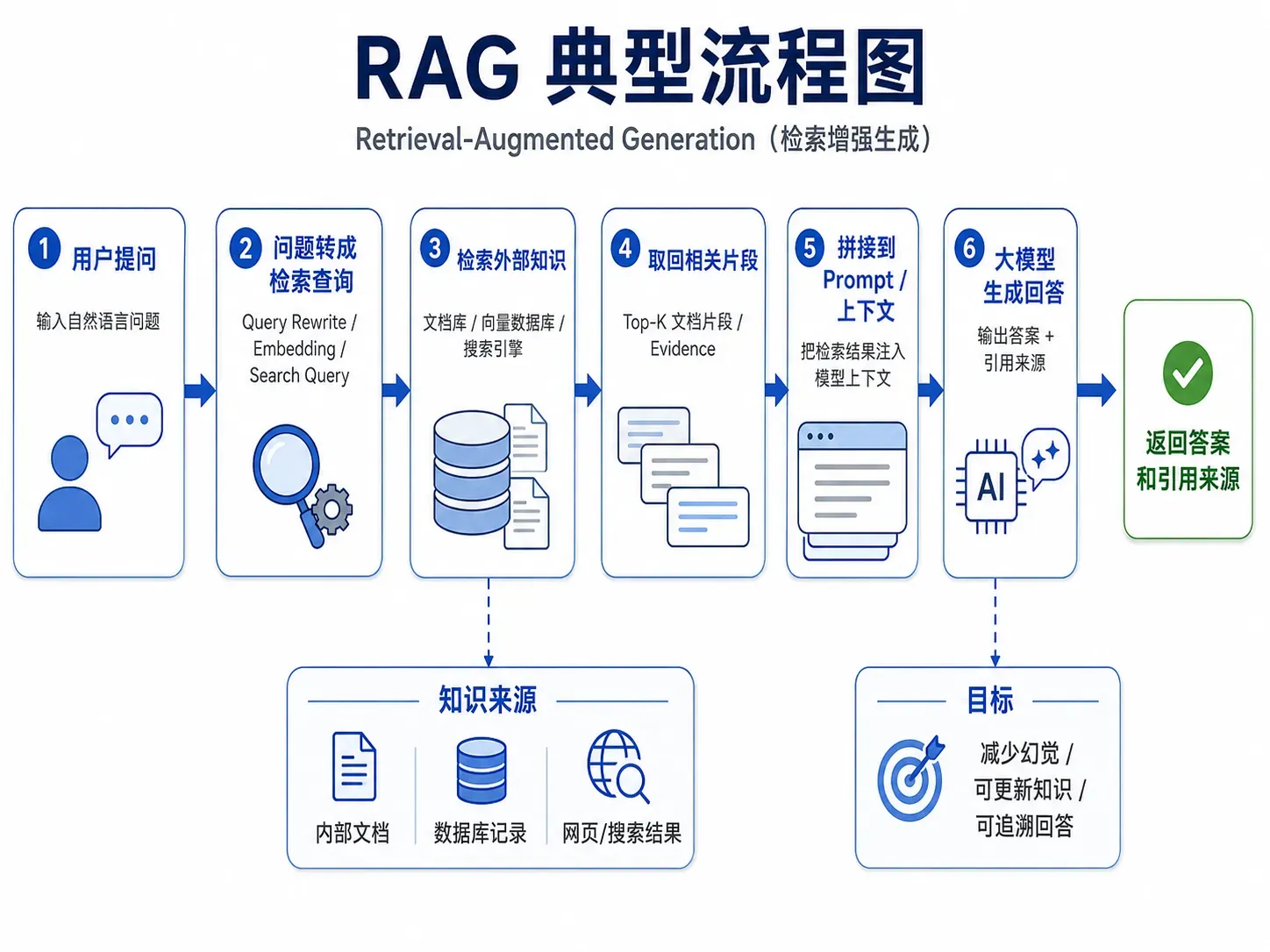
更准确地说,RAG 不等于知识库。
知识库是数据。
Embedding 是表示方式。
Vector DB 是存储和检索工具。
RAG 是把检索结果接入生成过程的架构。
可信 RAG 还要有 citation、faithfulness、abstention、eval。
所以:
有知识库 ≠ 有 RAG。
有向量库 ≠ 有可信 RAG。
很多“AI 知识库聊天机器人”只是做到了文档检索 + 模型回答,但还没有真正解决证据是否可靠、引用是否准确、回答是否忠实、证据不足时是否拒答这些问题。
RAG 的真正价值:不是知识更多,而是答案更可追溯
大模型的参数里确实存了大量知识,但这种知识有几个天然问题。
第一,它不一定新。
模型训练完成后,外部世界继续变化。政策会改,商品库存会变,订单状态会更新,公司内部文档会迭代。如果只依赖模型参数,知识更新成本很高。
第二,它不一定属于你的业务。
企业内部 SOP、用户简历、订单物流、客户服务记录、项目 README、私有代码文档,都不可能稳定存在于通用模型参数里。
第三,它很难给出 provenance,也就是可追溯的依据。
模型生成一个结论时,你很难知道它到底依据了哪份文档、哪段材料、哪条规则。
RAG 的核心价值就在这里:它把生成过程从纯参数记忆拉回到外部证据上。LangChain 文档把 retrieval 描述为在查询时获取相关外部知识,以增强 LLM 对上下文特定信息的回答能力;Spring AI 的 RAG 文档里,QuestionAnswerAdvisor 会查询向量数据库,把相关文档追加到用户文本中,为模型生成提供上下文。
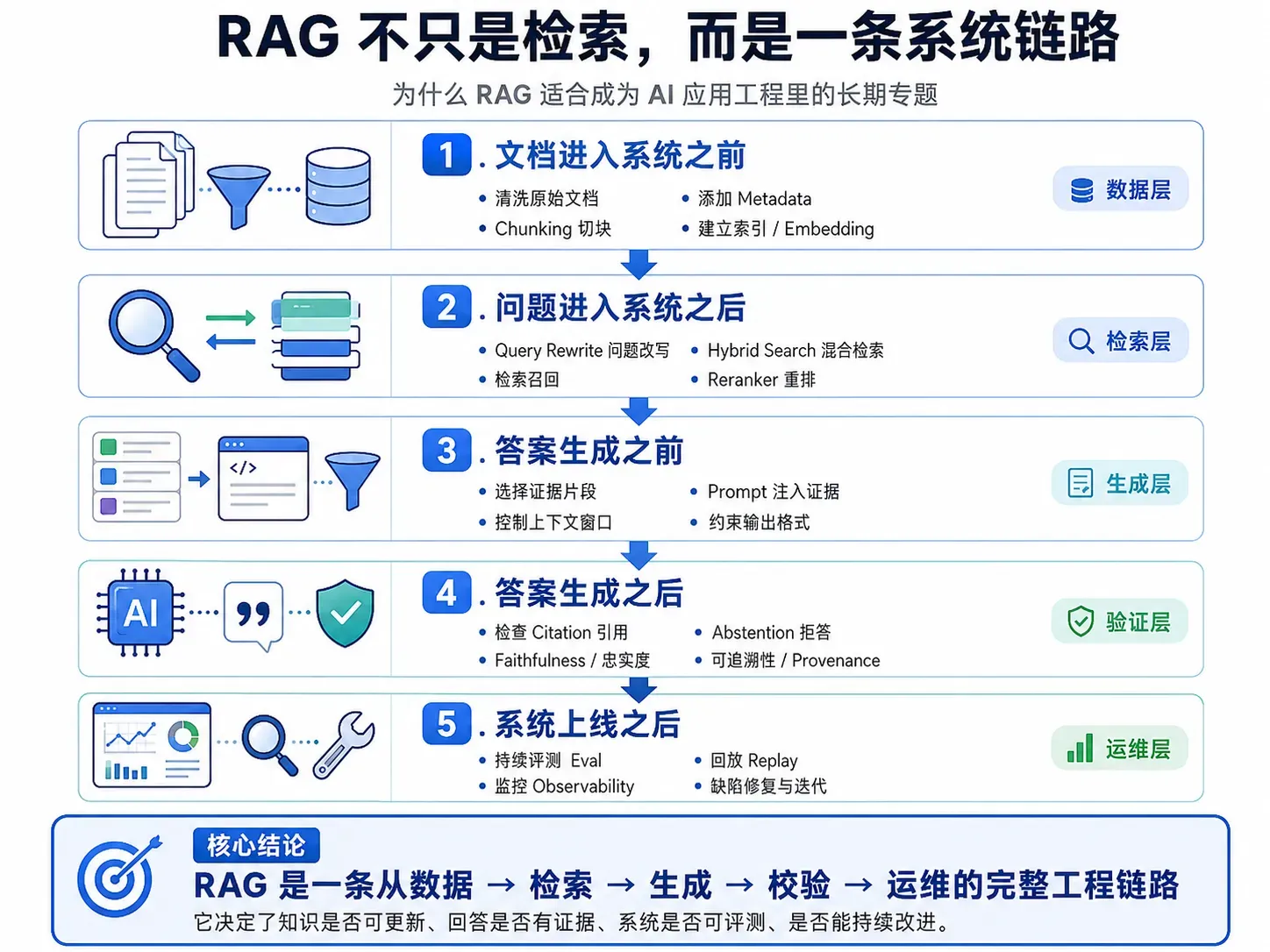
这也是为什么 RAG 很适合作为 AI 应用工程里的长期专题。它不是一个单点技术,而是一条系统链路:
文档进入系统之前,要清洗、切块、加元数据。
问题进入系统之后,要改写、检索、混合召回、重排。
答案生成之前,要选择证据、控制上下文、约束输出。
答案生成之后,要检查引用、忠实度、拒答、可追溯性。
系统上线之后,还要持续评测、监控、回放、修复。
如果只写“Embedding 是什么”“Vector DB 怎么用”,你只是在写 RAG 的零件。
真正值得写的是:这些零件如何共同决定一个 AI 应用是否可信。
第一个误区:只要接了知识库,就算有 RAG 了
很多人做 RAG 的第一个动作,是接一个向量数据库。
这当然重要。
有了 embedding 之后,需要一个地方存这些向量,并支持按相似度检索。这就是 Vector DB。
比如 pgvector 是 PostgreSQL 的开源向量相似搜索扩展,它可以让你在 PostgreSQL 里存向量,并支持精确或近似最近邻搜索、余弦距离、内积、L2 距离等能力。
如果你用 Java / Spring Boot / PostgreSQL 技术栈,PGVector 很适合作为入门和工程落地选择。因为你可以把 document、chunk、embedding、metadata、tenant_id 放在同一个 PostgreSQL 体系里,而不是一开始就维护单独的向量数据库集群。
但 Vector DB 不是 RAG 的全部。
Vector DB 解决的是:
这些 chunk 里,哪些和用户问题的向量最接近?它不解决:
这个 chunk 是否来自最新版文档?
这个 chunk 是否属于当前用户或当前租户?
这个 chunk 是否完整包含限制条件?
这个 chunk 是否真的能支撑答案?
模型是否忠实使用了这个 chunk?
证据不足时系统是否拒答?
所以不要把“接入向量库”误认为“完成了 RAG”。
如果你没有好的 chunk,没有 metadata filter,没有 citation,没有拒答,没有 eval,那它只是一个“向量检索 + Prompt”demo。
更准确地说:
Vector DB 负责存向量和查相似,但它不能自动保证答案可信。
第二个误区:只靠向量检索,就能找到正确证据
很多 RAG 教程会从 Embedding 开始。
Embedding 的确重要。OpenAI 文档把 embedding 定义为向量表示,并指出可以通过向量之间的距离衡量文本之间的相关程度。
简单说,Embedding 可以把一段文本变成一串数字,让系统按语义相似度检索内容。
比如用户问:
出差住酒店最多能报销多少钱?
文档里写的是:
差旅住宿报销标准:一线城市 600 元/晚,其他城市 400 元/晚。
这两句话词不完全一样,但意思相关。Embedding 能把它们映射到相近的向量空间里,让系统知道它们语义接近。
但真实系统里,只靠 Embedding 很容易出问题。
比如用户问:
退款政策第 7 条怎么说?
向量检索可能召回“售后政策总则”“退货流程说明”“跨境商品说明”,但漏掉真正包含“第 7 条”的精确条款。
用户问:
SKU-A1937 是否支持德国仓发货?
这里的关键不是语义相似,而是精确编号、地区、仓库、商品属性。BM25 / lexical search 这类词面检索反而更稳。
OpenSearch 文档把 BM25 描述为一种基于关键词的 lexical search 算法,会考虑词频、逆文档频率等因素来计算文档相关性。
所以,RAG 检索的第一条原则是:
不要迷信单一检索器。
Embedding 解决的是语义相似,不等于事实正确。
BM25 / lexical search 擅长词面匹配、编号、术语、错误码、固定表达。
Hybrid Search 把稀疏检索和稠密检索结合起来,降低漏召回风险。
RRF 可以把多个检索器的排序结果融合起来。
Reranker 再对候选结果做更精细的 query-document 匹配。
Qdrant 的 hybrid queries 文档也把 dense、sparse、多向量检索,以及 RRF、DBSF 等融合方式放在同一个检索框架下讨论。
一个最简 RAG demo 可能是:
query → embedding → vector db → answer但一个更接近生产的 RAG,应该更接近:
query
↓
query rewrite
↓
BM25 / lexical recall + vector recall
↓
RRF fusion
↓
rerank
↓
evidence selection
↓
answer generation
↓
citation / faithfulness check这条链路看起来复杂,但它解决的是同一个问题:
先尽可能不要漏掉证据,再尽可能把真正相关的证据排到前面。
第三个误区:把文档切碎,就等于做好了知识库
Chunking 是 RAG 里最容易被低估的环节。
很多人会直接用固定长度,比如 500 tokens 一个 chunk,50 tokens overlap。这个做法能跑,但不一定能用。
因为真实文档不是纯文本流。真实文档有标题、层级、表格、FAQ、代码块、步骤、异常说明、法律条款、商品参数、订单字段、版本记录。
如果你把一个退款规则从条件和例外之间切开,模型可能只看到“支持退款”,看不到“定制商品除外”。
如果你把项目架构图的说明和模块列表切散,模型可能知道用了 Redis,却不知道 Redis 是用于限流、缓存还是会话。
如果你把简历项目经历按固定长度切开,模型可能看到“AI 应用开发”,却看不到对应技术栈和结果证据。
所以 Chunking 的本质不是“把长文变短”,而是:
把文档切成适合被检索、被引用、被验证的证据单元。
好的 chunk 至少要满足几个条件:
它要足够小,小到能被精确召回。
它要足够完整,完整到能支撑一个回答 claim。
它要保留结构,例如标题、章节、来源、页码、版本、所属租户。
它要可追溯,生成答案时能反查原文位置。
它要可评测,能判断某个 query 是否应该召回它。
这也是为什么“RAG 做不好”很多时候不是模型问题,而是知识工程问题。
第四个误区:检索到相似内容,就等于找到了证据
相似,不等于正确。
这个问题在 RAG 里非常常见。
比如用户问:
这个订单还能退吗?
系统召回了一段“通用退款政策”,这当然相关。但它是否足够回答这个订单能不能退?
不一定。
因为这个问题还需要订单状态、商品类型、签收时间、是否定制商品、是否有质量问题、是否拆封等信息。
也就是说,检索到“相似内容”只说明系统找到了一些可能相关的文本,不代表它已经找到了足够支撑结论的证据。
这里至少有三层过滤。
第一层是 topK:最多取多少条候选 chunk。topK 太小,可能漏掉关键证据;topK 太大,可能把噪声塞进上下文。
第二层是 similarity threshold:相似度低于某个分数的结果不要。阈值太高,可能过滤掉有用证据;阈值太低,又会放进太多无关内容。
第三层是 metadata filter / tenant filter:只在正确范围里检索。
Metadata,就是文档或 chunk 附带的信息。
比如:
{
"tenantId"
"sourceType"
"language"
"version"
"status"
"updatedAt"
}用户问退款政策时,系统要先判断:
是不是当前商家的政策?
是不是当前语言?
是不是当前版本?
是不是 active 状态?
是不是当前用户有权限访问?
是不是对应业务线?
如果不做 metadata filter,系统可能召回旧版本政策、其他租户文档、测试文档、英文文档、无权限文档、已废弃规则。
这不是回答不准的问题,而是系统边界问题。
尤其在多租户系统里,tenant filter 不是 Prompt 约束,而是数据访问控制。你不能靠一句“请只回答当前商家的内容”来防止越权检索。真正的过滤应该发生在数据库查询、检索条件和权限系统里。
一句话总结:
RAG 不是在全库里找最像的内容,而是在正确范围里找能支撑答案的证据。
第五个误区:有引用,就说明答案可信
普通大模型胡说,用户至少还会怀疑:
它是不是编的?
但 RAG 系统一旦答错,问题反而更隐蔽。因为它通常会带着文档名、引用片段、相似度分数和来源链接,看起来像是经过检索验证的结果。
真正危险的不是 AI 没有依据,而是它拿着不完整、错误或不相关的依据,生成了一个看起来很确定的答案。
很多 RAG 系统会在回答后面附上引用来源,看起来很专业。但 citation 不等于 faithfulness。
引用只能说明:系统给了一个来源。
它不能自动说明:答案中的每一句都被这个来源支持。
举个例子。
原文说:
跨境定制商品非质量问题不支持七天无理由退货。
AI 回答:
所有跨境商品都不支持退货。
这个回答可能带着引用,但它把“定制商品”“非质量问题”“七天无理由”这些限定条件丢掉了。它不是没引用,而是引用不忠实。
所以 RAG 的可信问题至少要拆成三层:
Context relevance:检索到的上下文是否真的相关。
Groundedness / Faithfulness:回答是否被上下文支持。
Answer relevance:回答是否真正回应用户问题。
TruLens 的 RAG Triad 使用 context relevance、groundedness、answer relevance 三个维度来检查 RAG 应用;DeepEval 的 faithfulness 指标也强调要判断生成结果是否与 retrieval context 中的内容事实一致。
这三件事不能混在一起。
检索相关不代表生成忠实。
生成忠实不代表回答完整。
回答完整也不代表应该回答。
有些问题在证据不足时就应该拒答。
一句话总结:
Citation 问的是答案来自哪里,Faithfulness 问的是来源到底支不支持答案。
第六个误区:AI 应该永远给出答案
真正成熟的 RAG 系统必须有 abstention,也就是拒答能力。
当证据不足时,它应该说“不确定”。
当检索结果冲突时,它应该暴露冲突。
当问题超出知识库范围时,它应该说明边界。
当用户试图诱导它越权访问其他租户数据时,它应该拒绝。
当答案需要实时数据库状态,而当前只检索到静态文档时,它应该提示需要调用订单系统或业务 API。
很多 AI 应用失败,不是因为它答不出来,而是因为它在不该回答时回答了。
对客服系统来说,这可能是错误承诺。
对求职材料来说,这可能是简历造假。
对医疗、法律、金融来说,这可能是高风险误导。
对企业内部知识库来说,这可能是权限越界。
所以 RAG 不应该只追求“回答率”,还要追求“正确拒答率”。
一个可信 RAG 的目标不是让模型每次都有话说,而是让系统在证据不足、权限不足、上下文冲突或需要实时数据时,能主动暴露边界。
一句话总结:
可信 RAG 不应该永远回答,它应该知道什么时候不该回答。
第七个误区:问几个问题感觉不错,就可以上线
RAG demo 最危险的地方是:你问三五个问题,感觉它回答不错,就以为系统可用了。
但 RAG 的质量不能靠肉眼感受。你至少要把评测拆成两部分。
第一部分评测检索:
该召回的证据有没有召回?
相关 chunk 是否排在前面?
无关 chunk 是否污染上下文?
BM25、Embedding、Hybrid、RRF、Reranker 哪个环节带来了提升?
metadata filter 和 tenant filter 是否真的生效?
第二部分评测生成:
答案是否只基于证据?
引用是否准确?
是否遗漏关键限定条件?
是否在证据不足时拒答?
是否把多个来源中的冲突信息混成一个确定结论?
是否能把“不确定”说清楚,而不是装作知道?
RAGAS 论文把 RAG 评测拆成多个维度,包括检索系统能否识别相关且聚焦的上下文、LLM 是否忠实利用这些上下文、生成质量如何等;LangSmith 的 RAG 评测教程也会评估 RAG 应用;OpenAI 的评测最佳实践也强调,evals 应该是面向具体应用的测试,用来衡量 LLM 应用表现。
这就是 RAG Eval 的价值。它不是为了做漂亮分数,而是为了定位系统坏在哪里。
如果 retrieval recall 低,说明证据根本没进上下文。
如果 context precision 低,说明召回内容太脏。
如果 faithfulness 低,说明模型拿到了证据但没有忠实使用。
如果 answer relevance 低,说明回答没有解决用户问题。
如果 citation accuracy 低,说明引用链不可信。
如果 abstention accuracy 低,说明系统不知道什么时候不该回答。
从这个角度看:
RAG Eval 不是上线后的评分表,而应该是 RAG 开发的导航系统。
没有 eval 的 RAG,只能叫 demo;有 eval 的 RAG,才开始接近工程系统。
重新定义 RAG:从“能回答”到“可验证”
以前我会说:
RAG = Retrieval-Augmented Generation,检索增强生成。
现在我更愿意说:
RAG 是一种把外部证据引入生成过程,并通过检索、重排、引用、拒答和评测机制约束模型输出的 AI 应用架构。
这个定义更长,但更接近真实工程。
因为真实业务要的不是“AI 能说”,而是:
它引用的是不是正确来源?
它有没有越权拿到别人的数据?
它有没有遗漏关键例外条款?
它能不能承认证据不足?
它的回答能不能被回放、检查和复盘?
当知识库更新后,它能不能及时反映变化?
如果这些问题解决不了,RAG 就只是一个看起来更专业的聊天机器人。
如果这些问题解决了,RAG 才真正成为可信 AI 应用工程的底座。
接下来这个专题,我会按工程链路继续拆开写:
Embedding / Vector DB:语义表示和向量召回。
BM25 / Hybrid Search / RRF:降低只靠向量检索带来的漏召回。
Reranker:对候选证据重新排序。
Chunking:决定证据单元是否完整。
Metadata Filter / Tenant Filter:控制版本、权限和租户边界。
Citation / Faithfulness / Groundedness:判断答案是否真的被证据支持。
Abstention / RAG Eval:决定系统什么时候该拒答,以及如何证明它变好了。
但我不会把它们写成孤立概念。
每一个技术点都要回答同一个问题:
它能不能帮助 RAG 从“能回答”走向“可验证”?
我的目标不是证明“AI 能回答文档问题”,而是回答一个更硬的问题:
这个答案为什么值得被信任?
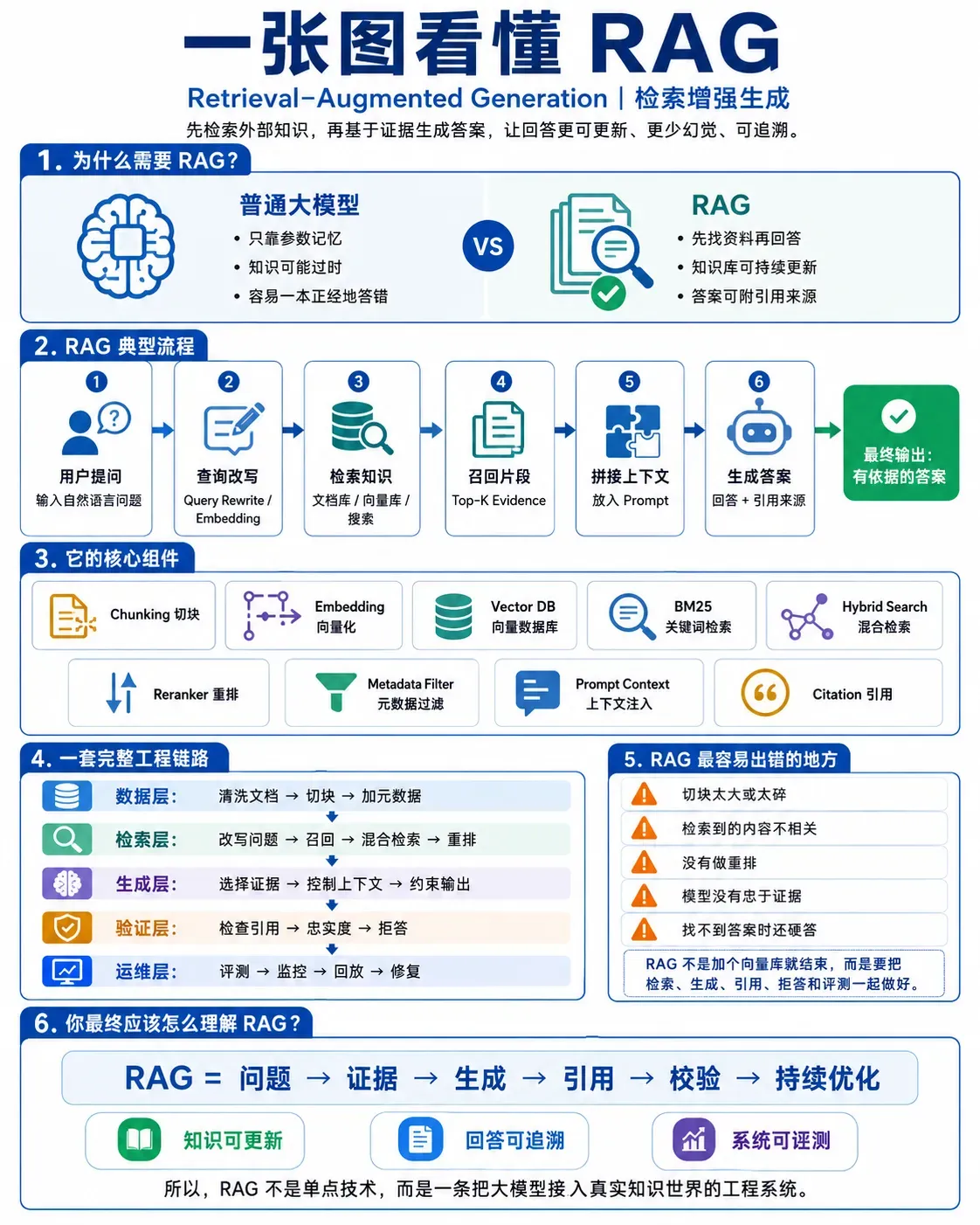
最后,用一张图把这篇文章的核心逻辑收束一下:
参考资料
[1] Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, NeurIPS 2020.
[2] LangChain Docs, Retrieval / RAG.
[3] Spring AI Reference, Retrieval Augmented Generation.
[4] OpenAI Docs, Vector embeddings.
[5] pgvector GitHub, Open-source vector similarity search for Postgres.
[6] OpenSearch Docs, Keyword search / BM25.
[7] Qdrant Docs, Hybrid Queries.
[8] Cormack et al., Reciprocal Rank Fusion, SIGIR 2009.
[9] RAGAS, Automated Evaluation of Retrieval Augmented Generation.
[10] TruLens Docs, RAG Triad.
[11] DeepEval Docs, Faithfulness Metric.
[12] LangSmith Docs, Evaluate a RAG application.
[13] OpenAI Docs, Evaluation best practices.
结语
下一篇,我会用类比讲透 RAG 的核心术语:Embedding、Chunk、Vector DB、BM25、Reranker 到底是什么。
我是 Ryan,一个专注于可信 AI 应用工程的开发者,个人技术博客:yanxai.com,研究如何让 AI 生成从“看起来对”走向“有证据、可追溯、可验证”。

