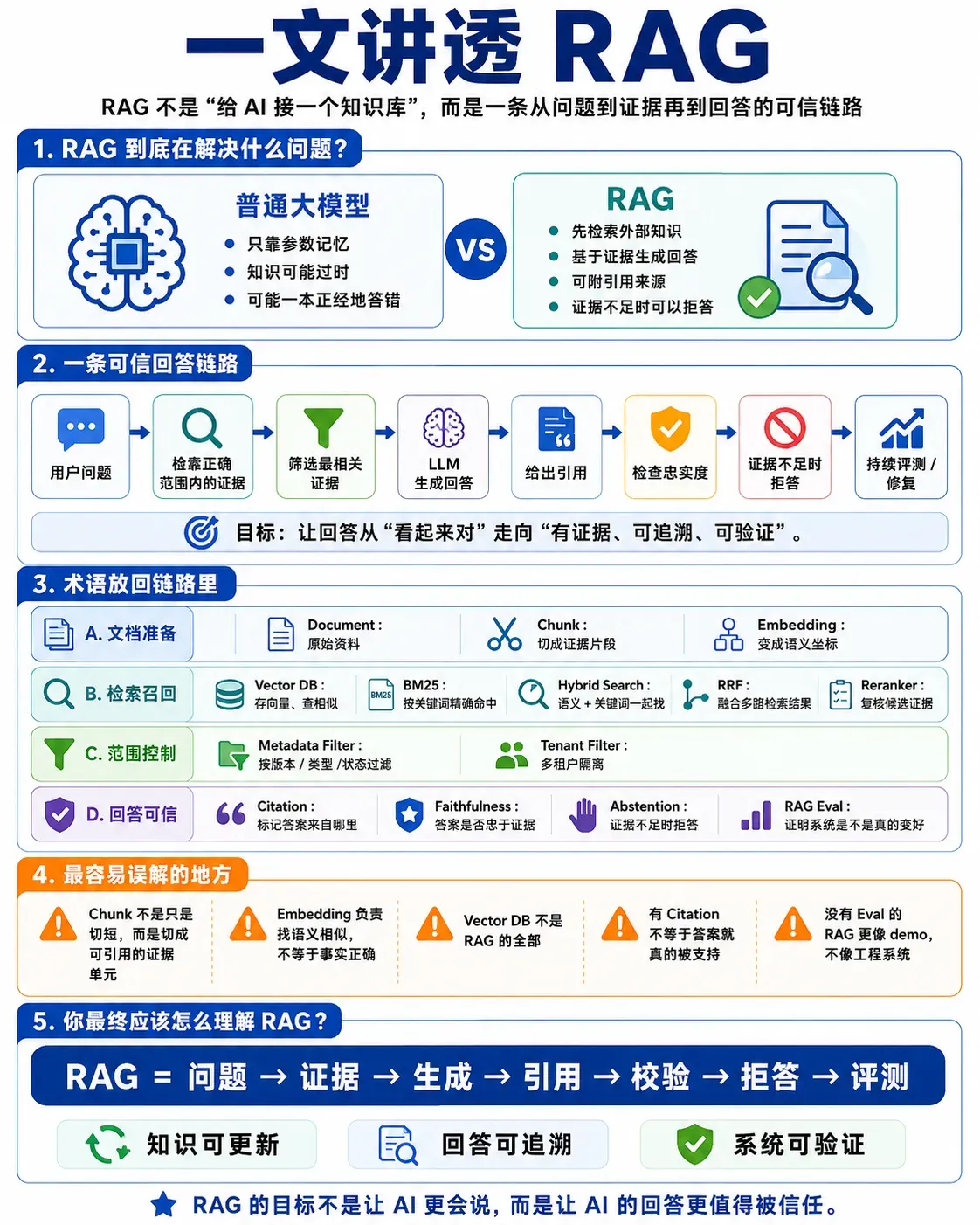
上一篇我写 RAG,不想把它讲成“给 AI 接一个知识库”。
因为知识库只是资料放在哪里,RAG 真正要解决的是:当 AI 给出一个答案时,我们能不能知道它依据了哪段材料、有没有遗漏限制条件、能不能在证据不足时拒答。
但如果继续往下讲 RAG,很快就会遇到一堆术语:
Embedding、Chunk、Vector DB、BM25、Reranker、Citation、Faithfulness、RAG Eval……
这些词如果直接堆出来,文章会很像技术名词表。读者看完还是不知道:它们到底在 RAG 系统里解决什么问题?
所以这一篇不写代码,不写复杂架构,只做一件事:
把 RAG 里的核心术语翻译成人话,并说明每个组件在“证据链”里负责什么。
如果把 RAG 看成一条可信回答链路,它大概是这样:
原始文档
↓
清洗 / 解析
↓
Chunking
↓
Embedding
↓
向量检索 / BM25 检索
↓
Hybrid Search
↓
RRF 融合排序
↓
Reranker 精排
↓
Final Evidence
↓
LLM 基于证据生成回答
↓
Citation / Faithfulness / Abstention
↓
RAG Eval这条链路看起来很长,但它其实只服务一个目标:
让 AI 的回答从“看起来对”,走向“有证据、可追溯、可验证”。
1. Document:原始资料
Document,就是进入知识库的原始资料。它可以是公司制度 PDF、产品说明书、客服 SOP、GitHub README、技术文档、Markdown 博客、简历、订单规则、FAQ,也可以是数据库里的业务记录。
Document 解决的是 RAG 里最基础的问题:
系统到底从哪里拿事实?
如果没有外部资料,模型只能依赖参数记忆。它可能知道一些通用知识,但不知道你的公司政策、项目文档、订单状态、内部流程、用户简历。
所以 Document 是 RAG 的原料。
但原始文档不能直接塞给模型。原因很简单:
- 太长。
- 太乱。
- 格式复杂。
- 版本不清楚。
- 里面可能有页眉、页脚、目录、广告、水印、重复段落。
- 有些信息已经过期。
- 有些信息不属于当前用户或当前租户。
所以进入 RAG 系统的第一步,不是 embedding,也不是向量库,而是文档治理:这份文档是谁的、从哪里来、什么时候更新、属于哪个业务线、是否有效、用户有没有权限看。
一句话总结:
Document 是 RAG 的事实来源,但原始文档本身还不是可用证据。
2. Chunk:证据片段
Chunk,就是把大文档切成一小段一小段,方便检索和引用。
很多人会把 chunking 理解成“把长文切短”,比如每 500 tokens 切一段,重叠 50 tokens。
这个理解太粗。
真正好的 chunk,不只是短,而是要成为一个“证据单元”。
比如一份退款政策里有这样一段:
定制商品非质量问题不支持七天无理由退货。若商品存在质量问题,用户需在签收后 7 日内提交图片或视频证据,客服审核后进入售后流程。
如果你把它切成两段:
- 第一段只保留“定制商品非质量问题不支持七天无理由退货”。
- 第二段只保留“用户需在签收后 7 日内提交证据”。
那模型可能在回答时丢掉条件,或者误解适用范围。
所以 chunk 的目标不是平均切短,而是:
把文档切成能被检索、被引用、被验证的最小证据单元。
好的 chunk 不只包含正文,还应该带上能追溯和过滤的信息,比如标题、章节、来源、页码、版本、所属租户、更新时间和权限范围。
比如:
{
"content"
"source"
"section"
"page"
"tenantId"
"version"
"updatedAt"
}这才是一个对 RAG 友好的 chunk。
一句话总结:
Chunk 不是把文档切短,而是把文档切成 AI 能使用、用户能追溯的证据片段。
3. Embedding:把文本变成语义坐标
Embedding 是 RAG 里最常被提到的词。
简单说,Embedding 就是把一段文本变成一串数字,也就是向量。
为什么要这么做?
因为计算机不能直接理解“这两句话意思很接近”。它需要一种可以计算的表示方式。
比如用户问:
出差住酒店最多能报销多少钱?
文档里写的是:
差旅住宿报销标准:一线城市 600 元/晚,其他城市 400 元/晚。
这两句话用词不完全一样。
用户说的是“出差”“住酒店”“最多能报销多少钱”,文档写的是“差旅”“住宿”“报销标准”。如果只靠关键词,系统不一定能稳定命中。但从语义上看,它们问的其实是同一类问题。
Embedding 的作用,就是把这些文本映射到一个向量空间里。你可以把它理解成“语义坐标”。
- 意思接近的文本,坐标距离更近。
- 意思不相关的文本,坐标距离更远。
所以在 RAG 里,Embedding 解决的是:
让系统可以计算用户问题和文档片段之间的语义相似度。
具体流程分成两个阶段。
第一阶段是文档入库,也就是提前处理知识库:
原始文档
↓
切成 chunk
↓
每个 chunk 做 embedding
↓
得到每个 chunk 的向量
↓
把 chunk 原文 + 向量 + metadata 存入数据库比如文档被切成三个 chunk:
chunk_001:差旅住宿报销标准:一线城市 600 元/晚,其他城市 400 元/晚。
chunk_002:交通费报销需提供发票。
chunk_003:餐饮补贴按城市等级计算。系统会把每个 chunk 都转成向量。真实的向量通常有几百到几千维,这里只用简化数字演示:
chunk_001 embedding = [0.12, -0.44, 0.87, ...]
chunk_002 embedding = [0.31, 0.22, -0.10, ...]
chunk_003 embedding = [-0.18, 0.62, 0.40, ...]这些数字不是给人看的,而是给系统计算相似度用的。
第二阶段是用户提问,也就是在线检索:
用户问题
↓
问题也做 embedding
↓
得到 query 向量
↓
拿 query 向量去数据库里查相似 chunk
↓
返回最相似的 topK 个 chunk
↓
把这些 chunk 原文交给 LLM 生成回答比如用户问:
出差住酒店最多能报销多少钱?
系统会把这个问题也转成向量:
query embedding = [0.10, -0.41, 0.83, ...]然后系统会比较:
query embedding 和 chunk_001 embedding 距离很近
query embedding 和 chunk_002 embedding 距离较远
query embedding 和 chunk_003 embedding 距离较远所以它会优先召回 chunk_001:
差旅住宿报销标准:一线城市 600 元/晚,其他城市 400 元/晚。
最后,LLM 不是凭空回答,而是基于召回的 chunk 生成:
根据差旅住宿报销标准,一线城市住宿最高可报销 600 元/晚,其他城市最高可报销 400 元/晚。
所以 Embedding 不是直接回答问题,它只负责把“可能相关的证据”找出来。
你可以把它理解成 RAG 检索层的第一步:
文档 chunk 先变成向量
用户问题也变成向量
系统比较两边向量的距离
距离越近,说明语义越相关
然后取回对应 chunk 原文
再交给大模型生成回答但这里有一个非常重要的边界:
Embedding 解决的是语义相似,不等于事实正确。
- 相似,不代表能回答。
- 相关,不代表完整。
- 语义接近,不代表证据足够。
比如用户问:
SKU-A1937 是否支持德国仓发货?
这个问题最关键的是两个精确信息:
SKU-A1937
德国仓系统必须找到同时和这两个条件相关的内容。
如果只靠 Embedding,它可能召回这些看起来相近的内容:
SKU-A1938 支持德国仓发货。
SKU-A1937 支持法国仓发货。
德国仓发货规则说明。这些内容都“相关”,但不一定能回答用户的问题。
因为用户问的不是“德国仓规则是什么”,也不是“类似 SKU 怎么发货”,而是:
SKU-A1937 这个具体商品,是否支持德国仓发货?
这种问题不能只靠语义相似,还需要 BM25 / 关键词检索、metadata filter,甚至直接查业务数据库。
所以不要把 Embedding 当成语义魔法。它只是 RAG 检索系统的一部分。
一句话总结:
Embedding 是 RAG 检索层的语义匹配器:它把文档片段和用户问题都变成向量,通过相似度找到可能相关的候选证据。但它只能说明“语义接近”,不能保证证据完整、事实正确、权限合规,也不能替代关键词检索和业务数据查询。
4. Vector DB:存向量、查相似
有了 embedding 之后,需要一个地方存这些向量,并支持按相似度检索。
这就是 Vector DB。
常见选择包括 PGVector、Milvus、Qdrant、Weaviate、Pinecone,也可以使用 Elasticsearch / OpenSearch 的向量检索能力。
Vector DB 的基本工作方式是:
- 文档被切成 chunk。
- 每个 chunk 被 embedding 成向量。
- 向量和 chunk 一起存入数据库。
- 用户提问时,问题也被 embedding 成向量。
- 系统查找和问题向量最相似的 chunk。
- 把这些 chunk 交给大模型生成答案。
基本流程:
chunk 文本
↓
embedding 模型
↓
向量
↓
Vector DB
↓
相似度检索
↓
topK chunks如果你用 Java / Spring Boot / PostgreSQL 技术栈,PGVector 是一个很适合入门和工程落地的选择。它是 PostgreSQL 的向量相似搜索扩展,可以让你在 PostgreSQL 里存向量、建索引、做相似度查询。
对个人项目和中小型应用来说,PGVector 的优势是工程成本低:document、chunk、metadata、tenant_id 可以和业务数据放在同一个 PostgreSQL 里,也方便接入 Spring AI 的 VectorStore 抽象,不需要一开始就维护单独的向量数据库集群。
但 Vector DB 不是 RAG 的全部。
很多人做 RAG 的第一个误区就是:
我接了向量数据库,所以我有 RAG 了。
不一定。
如果你没有好的 chunk,没有 metadata filter,没有 citation,没有拒答,没有 eval,那它只是一个“向量检索 + Prompt”demo。
用一个生活类比:
假设你有一个图书馆。
- Document 是一本本书。
- Chunk 是书里被裁出来的一小段内容。
- Embedding 是给每一段内容贴一个“语义坐标”。
- Vector DB 是图书馆的“语义索引系统”。
- 用户问题也会被贴一个“语义坐标”。
- 系统就看:用户问题这个坐标,离哪些内容的坐标最近。
- 最近的几段,就是候选证据。
所以 Vector DB 不是“知识库本身”的全部,它只是知识库里的一个检索组件。
一句话总结:
Vector DB 负责把 chunk 的语义坐标存起来,并在用户提问时找出最相似的候选证据;但证据是否完整、是否有权限、是否支持答案,还要靠 chunk 质量、metadata filter、reranker、citation、faithfulness 和 eval。
5. topK:到底取多少条证据
topK 是一个很小但很重要的参数。
它表示:检索时取前 K 条结果。
比如:
topK = 5意思是:系统会取最相似的 5 个 chunk 放进上下文。
很多人会以为 topK 越大越好,因为取更多证据似乎更安全。
但真实情况不是这样。
- topK 太小,可能漏掉关键证据。
- topK 太大,可能引入噪声,污染上下文。
- 无关 chunk 进入 prompt 后,模型可能把错误信息也编进答案。
- 上下文越长,成本越高,延迟越大。
比如用户问住宿报销标准,topK 太小可能只拿到金额,漏掉“必须提供发票”;topK 太大又可能把交通费、餐饮补贴、加班餐费一起塞进上下文,污染回答。
如果 topK 太小,比如 topK = 1:
只取第 1 条 chunk好处是上下文很干净,成本低,速度快。
但风险是:如果第 1 条不完整,系统就漏掉关键条件。
比如第 1 条只说:
一线城市住宿最高 600 元/晚。但第 4 条才说:
报销时必须提供住宿发票,且需经过部门负责人审批。如果 topK = 1,模型只能看到第一条,就可能回答不完整。
这叫:漏召回。
如果 topK 太大,比如 topK = 20:
取前 20 条 chunk看起来证据更多,好像更安全。
但问题是,前 20 条里很可能混进很多“看起来相关但其实没用”的内容:
差旅住宿标准
交通费规则
餐饮补贴
出差审批
酒店协议
员工福利
加班餐费
团队建设报销……这些内容一起塞进 Prompt,模型可能被干扰。
用户问的是“住宿最高报销多少”,但上下文里混入“餐饮补贴”“交通费”“加班餐费”,模型就可能把不相关规则也带进答案。
这叫:噪声污染上下文。
所以 topK 的本质是一个平衡:
topK 太小:容易漏掉关键证据
topK 太大:容易引入无关噪声所以 topK 不是越大越好,而是要和 chunk 质量、检索质量、reranker、上下文窗口一起调。
比如:
- naive RAG 可能直接取 top5。
- Hybrid Search 可能先召回 top50。
- Reranker 再从 top50 里选 top5。
- 最终只把最可靠的 3–5 个 chunk 放进 prompt。
topK也分两种,第一种是:召回阶段的 topK。
它的目标是“不要漏”。
比如:
Vector Search 先召回 top50
BM25 也召回 top50这时候 topK 可以大一点,因为只是候选池,还没直接塞进 Prompt。
第二种是:最终上下文的 topK。
它的目标是“少噪声”。
比如 reranker 从 top50 里重新排序,最后只选:
final topK = 3 或 5这几条才会真正进入 Prompt,让 LLM 生成答案。
所以完整流程是:
用户问题
↓
向量检索 / BM25 检索
↓
先多召回一些候选证据,比如 top50
↓
Reranker 重排
↓
最终只选 top3~top5
↓
放进 Prompt
↓
LLM 生成答案一句话总结:
topK 决定有多少候选证据进入下一步,太少会漏召回,太多会污染上下文。
6. Similarity Threshold:相似度阈值
Similarity Threshold,就是相似度低于某个分数的结果不要。
比如:
similarityThreshold = 0.75意思是:相似度低于 0.75 的 chunk 不进入上下文。
它的作用是减少无关内容进入 prompt。
但这个参数也不能迷信。
- 阈值太高,可能把有用证据过滤掉。
- 阈值太低,可能放进很多噪声。
- 不同 embedding 模型、不同业务问题、不同 query 长度都会影响分数分布,所以 threshold 不能照抄,需要靠 eval 调。
Similarity Threshold 可以理解成:检索结果的最低及格线。
Similarity Threshold 的本质是一个平衡:
阈值太高:结果更干净,但可能漏掉有用证据
阈值太低:结果更多,但可能引入噪声它和 topK 的区别也要分清。
topK 控制的是:
最多取几条Similarity Threshold 控制的是:
低于多少分不要比如:
topK = 5
similarityThreshold = 0.75意思不是“无论如何取 5 条”,而是:
先按相似度排序最多取前 5 条但低于 0.75 的不要假设结果是:
0.91:chunk A
0.86:chunk B
0.79:chunk C
0.68:chunk D
0.62:chunk E虽然 topK = 5,但因为 threshold = 0.75,最后只保留:
chunk A
chunk B
chunk C所以可以这样理解:
topK 是数量上限
threshold 是质量底线一句话总结:
topK 决定“最多拿几条”,Similarity Threshold 决定“太不像的不要”。
7. BM25 / Lexical Search:关键词检索不是过时技术
BM25 或 lexical search,可以简单理解成关键词检索。
它不像 embedding 那样理解语义,而是更关注词面命中。
比如:
SKU-A1937
HTTP 401
退款政策第 7 条
tenant_id
RetrievalAugmentationAdvisor
PGVector这些查询不需要先“理解语义”,而是要精确命中。
如果用户问“SKU-A1937 是否支持德国仓发货”,系统就应该优先找到包含 SKU-A1937 的文档或表格。
如果用户问“Spring AI 的 RetrievalAugmentationAdvisor 怎么用”,系统就应该优先命中官方文档里包含这个类名的片段。
所以 BM25 / lexical search 没有过时。
它解决的是向量检索不擅长的问题:
- 编号。
- 错误码。
- 字段名。
- 类名。
- 方法名。
- 产品型号。
- 政策条款。
- 固定术语。
- 短 query。
- 中英混合表达。
这也是为什么很多生产 RAG 系统会做 Hybrid Search,而不是只做向量检索。
BM25 / Lexical Search 这段的核心意思是:
不要以为 RAG 只靠 Embedding。Embedding 擅长找“意思相近”的内容,但 BM25 擅长找“字面上必须命中”的内容。
你不需要记 BM25 的公式,只要理解它比普通关键词匹配更会衡量词的重要性和匹配强度,特别适合编号、类名、字段名、错误码、政策条款这类必须精确命中的内容。
你只要理解:BM25 更重视词面命中,尤其适合查精确词。
如果用 Embedding,系统可能觉得这些内容相关:
HTTP 403 权限错误
HTTP 401 未认证
HTTP 500 服务异常但如果用户明确问 HTTP 401,那系统就必须优先命中包含 HTTP 401 的片段。
这就是 BM25 的价值。
它不是过时技术,而是在 RAG 里补 Embedding 的短板。
更具体一点,Embedding 容易在这些场景失手:
比如用户问“退款政策第 7 条怎么说?”,Embedding 可能召回退款政策总则、退款流程、售后说明,但不一定精确命中“第 7 条”。BM25 会更关注“第 7 条”这个词面。
一句话总结:
Embedding 找语义相似,BM25 / lexical search 找精确命中。
8. Hybrid Search:两路一起找证据
Hybrid Search,就是混合检索。
最常见的是:
Vector Search + BM25 / Lexical Search也就是:
向量检索负责找语义相关。
关键词检索负责找精确命中。
两路结果合并后再排序。
它解决的是一个非常现实的问题:
单一路检索器容易漏证据。
比如:
用户问:
我的简历里有没有能支撑 RAG evaluation 的证据?
简历里可能没写 “RAG evaluation”,但写了:
设计了 evidence guard、citation check、unsupported claim detection,用于限制 AI 生成中的无证据扩写。
这个时候向量检索有价值。
但如果用户问:
我的项目有没有写 PGVector?
那就应该精确命中 PGVector 这个词,关键词检索更重要。
所以 Hybrid Search 不是炫技,而是降低漏召回。
基本流程是:
用户问题
↓
Vector Recall:找语义相关
+
Lexical Recall:找精确命中
↓
融合排序/去重/重排
↓
候选证据Vector Search 像一个懂意思的人:
“你虽然没说 evidence guard,但我知道它和 RAG evaluation 有关。”
BM25 像一个认真查关键词的人:
“你问 PGVector,我就必须找到 PGVector 这个词。”
一句话总结:
Hybrid Search = 语义检索负责“意思相近”,关键词检索负责“原词命中”。两路一起召回,可以降低关键证据被漏掉的概率。
9. RRF:把多路检索结果合并
Hybrid Search 会产生两张排行榜,RRF 的作用就是把这两张排行榜合并成一张总榜。
做完 Hybrid Search 后,会出现一个新问题:
- Vector Search 有一组结果。
- BM25 / Lexical Search 有一组结果。
- 这两组结果怎么合并?
最直接的想法是把分数加起来。
但这通常不严谨。
因为向量相似度和 BM25 分数不是同一种分数。它们来自不同算法,尺度不同,不能简单相加。
这时候可以用 RRF。
RRF,全称 Reciprocal Rank Fusion,中文可以理解成“倒数排名融合”。
它不直接比较原始分数,而是看排名。
公式大概是:
RRF score = Σ 1 / (k + rank)不用被公式吓到,它的意思很简单:
- 如果一个 chunk 在向量检索里排得很靠前,在关键词检索里也排得靠前,那它更可能重要。
- 如果一个 chunk 只在某一路检索里非常靠前,它也有机会被保留下来。
- RRF 关心的是“排第几”,不是原始分数是多少。
举个简单例子:
Chunk A:向量检索第 1,关键词检索第 5
Chunk B:向量检索第 20,关键词检索第 1
Chunk C:向量检索第 3,关键词检索没有召回RRF 会综合这些排名,而不是强行比较“向量相似度 0.82”和“BM25 分数 12.7”谁更大。
RRF 最适合解决的问题是:
Vector Search 和 BM25 的分数不能直接加,但它们的排名可以融合。你可以把它放回整个 RAG 流程:
用户问题
↓
Vector Search 返回一组排行榜
↓
BM25 返回一组排行榜
↓
RRF 根据“排名”融合两组结果
↓
得到候选证据总榜
↓
Reranker 再精排
↓
选出 Final Evidence这里还要分清 RRF 和 Reranker:
RRF:用排名规则快速融合多路检索结果
Reranker:用模型进一步判断 query 和 chunk 是否真的相关一句话总结:
RRF 是把 Vector Search 和 BM25 的结果合并成一张更合理的候选证据排行榜。
10. Reranker:最终复核候选证据
Retriever 是粗筛,Reranker 是复核。
- 检索器先找出一批候选 chunk,比如 top50 或 top100。
- Reranker 再判断这些 chunk 和当前问题到底有多相关。
- 最后只选最适合回答问题的几个 chunk 进入 prompt。
为什么要这样做?
因为召回阶段追求“不要漏”。
重排阶段追求“更准确”。
- 如果一开始就只取 top5,很可能漏掉关键证据。
- 如果把 top50 全部塞进 prompt,又会污染上下文。
- 所以常见做法是:先多召回,再精排。
典型流程:
用户问题
↓
Vector Search / BM25 先召回 top50
↓
RRF 把多路结果融合成候选列表
↓
Reranker 逐条判断:这个 chunk 到底能不能回答这个问题?
↓
重新排序
↓
只选 top3 / top5 放进 Prompt
↓
LLM 基于最终证据生成答案Reranker 和 Embedding 的区别非常重要。
Embedding 的做法一般是:
把 query 单独变成向量
把 chunk 单独变成向量
然后计算两个向量距离它更像是快速粗筛:
这个问题和这个 chunk 的语义大概像不像?Reranker 的做法通常是:
把 query 和 chunk 放在一起让模型直接判断它们的相关性它问的是更细的问题:
这个 chunk 是否真的能回答当前 query?
这个 chunk 是强相关、弱相关,还是只是沾边?
这个 chunk 是否包含用户问题需要的关键条件?举个例子。
用户问:
退款政策第 7 条怎么说?前面检索可能召回:
A:退款政策总则
B:退款申请流程
C:第 7 条:定制商品非质量问题不支持七天无理由退货
D:售后审核要求
E:退货运费说明Embedding 可能觉得 A、B、D、E 都和“退款政策”相关。
但 Reranker 会更容易判断:
用户问的是“第 7 条”
C 直接包含“第 7 条”
所以 C 应该排第一这就是 reranker 的价值:它不是只看大概相关,而是更细地判断“能不能支撑这个问题”。
一句话总结:
Reranker 是 final context 之前的最后一道证据复核:它决定哪些候选 chunk 真正有资格进入大模型上下文。
11. Metadata Filter:只在正确范围里检索
很多 RAG demo 会直接在所有文档里检索,但生产系统不能这样做。
Metadata,就是文档或 chunk 附带的信息。
比如:
{
"tenantId"
"sourceType"
"language"
"version"
"status"
"updatedAt"
}Metadata Filter 就是按这些字段过滤。
为什么它重要?
因为不是所有文档都应该被检索。
用户问退款政策时,系统要先判断:
- 是不是当前商家的政策?
- 是不是当前语言?
- 是不是当前版本?
- 是不是 active 状态?
- 是不是当前用户有权限访问?
- 是不是对应业务线?
如果不做 metadata filter,系统可能召回:
- 旧版本政策。
- 其他租户文档。
- 测试文档。
- 英文文档。
- 无权限文档。
- 已废弃规则。
这不是回答不准的问题,而是系统边界问题。
RAG 检索时,不能在所有文档里乱找。它必须先限定范围,只在“当前用户应该看的、当前业务应该用的、当前版本有效的文档”里检索。
Chunk 本身是正文,比如:
定制商品非质量问题不支持七天无理由退货。Metadata 是这段 chunk 身上的标签,比如:
{
"tenantId"
"sourceType"
"language"
"version"
"status"
"updatedAt"
}这些标签不是给大模型看的废信息,而是给系统检索时做过滤用的。
也就是说,系统不是直接问:
哪些 chunk 和用户问题最相似?而应该先问:
在当前商家 merchant_001 的 active 中文退款政策里,哪些 chunk 和用户问题最相似?这就是 Metadata Filter。
一句话总结:
Metadata Filter 决定“哪些资料有资格参与检索”;Embedding / BM25 决定“这些资料里哪些最相关”。
12. Tenant Filter:多租户系统的硬隔离
Tenant Filter 可以理解成 Metadata Filter 里最不能出错的一种。
Metadata Filter 是范围控制,Tenant Filter 是权限隔离。
如果一个系统服务多个公司、多个商家、多个团队,每个组织就是一个 tenant。
比如:
- 商家 A 有自己的退款政策。
- 商家 B 有自己的退款政策。
- 商家 C 有自己的商品知识库。
用户来自商家 A,那么系统只能检索商家 A 的文档。
不能靠 prompt 说:
请你只回答当前商家的内容。
这不够。
真正的 tenant filter 应该在数据库查询、检索条件、权限系统里生效。
比如:
WHERE如果 tenant filter 漏了,后果不是“回答不够好”,而是“数据越权”。
一句话总结:
Tenant Filter 不是 Prompt 约束,而是数据访问控制。
13. Citation:答案来自哪里,但不代表答案一定被支持
Citation,就是引用来源。
它告诉用户:
- 这个答案来自哪篇文档。
- 来自哪个 chunk。
- 来自哪一页。
- 来自哪个章节。
- 原文片段是什么。
比如:
{
"answer"
"citation"
"document"
"section"
"page"
"quote"
}
}Citation 的价值是让答案可追溯。
但要注意:
有引用不等于可信。
引用只能说明系统给了来源。
它不能自动说明答案真的被来源支持。
比如原文说:
定制商品非质量问题不支持七天无理由退货。
模型回答:
所有跨境商品都不支持退货。
这个答案可能也带了引用,但它扩大了原文范围,所以不可信。
一句话总结:
Citation 是可信的起点,不是终点。
14. Faithfulness / Groundedness:答案是否忠于证据
Faithfulness 和 Groundedness 经常一起出现。
你可以先不用纠结二者的边界,它们都在问一个核心问题:
模型说的话,证据里到底有没有?
如果证据说:
候选人参与了 Spring Boot 后端开发,并接入了 Redis 限流。
模型改写成:
主导设计高并发 AI Agent 平台,使用 Redis、RocketMQ、PGVector 构建生产级 RAG 系统。
这就是典型不 faithful。
因为模型加了很多证据里没有的东西。
这在 AI 简历、项目包装、求职材料里尤其危险。它不是简单“润色”,而是把没有证据的经历写成了事实。
所以 Faithfulness / Groundedness 不是看答案是否流畅,也不是看答案是否有引用,而是看:
答案里的每个关键 claim 是否被证据支持。
你可以把它拆成 claim 检查:
Claim 1:主导设计高并发 AI Agent 平台证据支持?没有。
Claim 2:使用 Redis证据支持?有。
Claim 3:使用 RocketMQ证据支持?没有。
Claim 4:使用 PGVector证据支持?没有。
Claim 5:构建生产级 RAG 系统证据支持?没有。所以 Faithfulness 检查的不是“这句话写得好不好”,而是:
每一个关键 claim 是否有证据支撑?
有没有夸大?
有没有扩展范围?
有没有补充证据里没有的技术?
有没有把参与说成主导?
有没有把 demo 说成生产级?这也是为什么 Faithfulness 不能只看语言是否流畅,也不能只看答案是否带了引用。
因为模型最容易出现的问题就是:它可以把错误答案说得非常自然。
一个不 faithful 的答案可能具备这些表象:
语言很流畅结构很清楚看起来专业甚至带了引用但只要答案里的关键结论没有被证据支持,它仍然不可信。
一句话总结:
Citation 问的是“答案挂了哪个来源”,Faithfulness 问的是“这个来源到底支不支持答案”。有引用只是把答案和资料连起来;Faithfulness 才是在检查这条连接是不是真的成立。
15. Abstention:证据不足时,系统应该拒答
Abstention,就是拒答。
但这里的拒答不是“模型不会”,而是“系统知道不该答”。
什么时候应该拒答?
- 没有检索到证据。
- 证据之间互相冲突。
- 用户没有权限访问相关资料。
- 问题超出知识库范围。
- 答案需要实时订单状态,但当前只有静态政策文档。
- 检索结果只支持一部分结论,不支持完整回答。
比如用户问:
这个订单还能退吗?
如果系统只检索到通用退款政策,但没有订单状态、商品类型、物流节点、是否定制商品这些信息,就不应该直接回答“可以退”或“不可以退”。
更好的回答是:
当前知识库只包含通用退款政策,无法确认该订单是否符合退款条件。需要查询订单状态、商品类型和物流信息后才能判断。
这就是可信 RAG 的边界感。
一句话总结:
可信 RAG 不应该永远给答案。它必须能识别证据不足、权限不足、信息缺失和结论无法成立的情况。
16. RAG Eval:证明系统真的变好了
RAG Eval,就是评测 RAG 系统是不是真的有效,要用一组可重复的测试问题,检查系统到底坏在哪个环节。
很多 demo 的评测方式是:
- 问几个问题。
- 看起来回答不错。
- 觉得系统可以上线。
这很危险。
因为 RAG 的错误可能发生在多个环节:
- 文档解析错。
- chunk 切坏了。
- embedding 召回错。
- BM25 没命中。
- RRF 排序不好。
- reranker 选错证据。
- final context 被噪声污染。
- 模型没有忠实使用证据。
- 引用不支持答案。
- 该拒答时没有拒答。
所以 eval 的价值不是打一个漂亮分数,而是定位系统坏在哪里。
常见评测维度包括:
- retrieval recall:该召回的证据有没有召回。
- context precision:召回的上下文有多少真的有用。
- faithfulness:答案是否忠于证据。
- answer relevance:答案是否回应问题。
- citation accuracy:引用是否真的支持答案。
- abstention accuracy:该拒答时有没有拒答。
RAG 不是一个单点功能,而是一条链路:
文档解析
↓
chunk 切分
↓
embedding / BM25 召回
↓
RRF / Reranker 排序
↓
final context 选择
↓
LLM 生成回答
↓
citation 引用
↓
faithfulness 检查
↓
abstention 拒答这条链路任何一环出问题,最后答案都可能错。
一句话总结:
没有 Eval,你只能凭感觉调 RAG。
有了 Eval,你才能知道问题到底出在检索、排序、上下文选择、生成、引用,还是拒答边界。
到这一步,RAG 才开始从 demo 接近工程系统。
17. 把这些词放回一条证据链里
现在再回头看这些术语,它们其实不是孤立概念。
- Document 是原料。
- Chunk 是证据单元。
- Embedding 是语义坐标。
- Vector DB 是语义检索工具。
- BM25 / Lexical Search 是精确词面检索工具。
- Hybrid Search 是双路召回。
- RRF 是多路排序融合。
- Reranker 是候选证据复核。
- Metadata Filter 是检索范围控制。
- Tenant Filter 是数据隔离。
- Citation 是来源标记。
- Faithfulness / Groundedness 是答案是否忠于证据。
- Abstention 是边界控制。
- RAG Eval 是质量证明。
它们共同组成的是:
问题
↓
检索正确范围内的证据
↓
选择最能支撑答案的证据
↓
基于证据生成回答
↓
标记引用来源
↓
检查答案是否忠于证据
↓
证据不足时拒答
↓
用 eval 证明系统是否变好这就是我理解的可信 RAG。
- 它不是“向量库 + Prompt”。
- 也不是“把 PDF 丢进去让 AI 聊天”。
- 它是一套把问题、证据、生成、引用、拒答、评测串起来的工程系统。
18. 下一篇:从 0 到 1 搭一个个人技术资产知识库
下一篇,我会开始写保姆级实战:
从 0 到 1 搭一个个人技术资产知识库:Spring Boot + Spring AI + PGVector 保姆级教程。
这次不做泛泛的“PDF 聊天机器人”,而是用自己的真实技术资产作为知识库来源:
个人博客文章
GitHub README
项目文档
技术复盘
Markdown 笔记
目标也不是一上来做完整企业级平台,而是搭出一个最小可信 RAG 骨架:
文档从哪里来
chunk 怎么切
embedding 怎么入库
PGVector 怎么检索
metadata 怎么过滤
回答怎么带 citation
证据不足怎么拒答
retrieval trace 怎么记录
最小 eval case 怎么设计
它还不是完整企业级知识库,但会保留企业级系统最关键的边界意识:来源、权限、版本、证据、引用、拒答和评测。
最后回到一句话:
RAG 的目标不是让 AI 更会说,而是让 AI 的回答更值得被信任。
参考资料
Patrick Lewis et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020 / arXiv:2005.11401.
https://arxiv.org/abs/2005.11401Spring AI Reference Documentation. Retrieval Augmented Generation.
https://docs.spring.io/spring-ai/reference/api/retrieval-augmented-generation.htmlpgvector. Open-source vector similarity search for Postgres. GitHub.
https://github.com/pgvector/pgvectorGordon V. Cormack, Charles L. A. Clarke, Stefan Büttcher. Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods. SIGIR 2009.
https://research.google/pubs/reciprocal-rank-fusion-outperforms-condorcet-and-individual-rank-learning-methods/Shahul Es et al. RAGAS: Automated Evaluation of Retrieval Augmented Generation. EACL 2024 / arXiv:2309.15217.
https://arxiv.org/abs/2309.15217
我是 Ryan,一个专注于可信 AI 应用工程的开发者,技术博客:yanxai.com。相比让 AI 生成更多内容,我更关心它的回答是否有证据,过程是否可追溯,结果是否经得起验证。
